一、概况:计算平台是自动驾驶系统“大脑”,供应生态多样
核心结论:自动驾驶汽车围绕感知、决策和执行三大环节构建软硬件系统。车载智能计算平台是自动驾驶 汽车的“大脑”,主要负责完成感知环节的识别融合任务以及整个决策环节,需要处理海量数据和进行复杂的 逻辑运算。为满足高算力需求,目前车载智能计算平台集成多个 SoC,每个 SoC 集成多类计算单元(如 CPU、 GPU、FPGA、ASIC 等)。同时,车载智能计算平台还需要高效的软件架构支持应用开发。其软件架构高度分 层化和模块化,主要分为系统软件(虚拟机、操作系统和中间件)、功能软件和应用程序三层。相较于传统零 部件,车载智能计算平台涉及各类芯片和软件,供应商来自不同领域,供应生态多样。主要有三类参与者:OEM 主要负责应用软件和部分功能软件,传统 Tier1 在中间层布局较深,芯片商提供硬件以及部分系统软件。另外 还有算法方案解决商、Robotaxi 厂商、专业系统软件商等。

1.1 自动驾驶系统架构:传感器+车载智能计算平台+执行系统
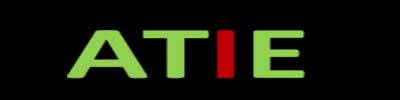
自动驾驶系统是一个复杂的系统。为实现从 A 地到 B 地的驾驶过程,需要自动驾驶系统完成感知、决策、 执行 3 大任务。
感知:感知环节是实现自动驾驶的前提和基础,其主要功能是解决 2 个问题:环境识别(周边环境如何) 和自身定位(在哪里)。环境识别(周边环境如何):感知系统利用摄像头、激光雷达、毫米波雷达、超声波 雷达等传感器获取道路环境的信息,并对传感器数据进行处理、融合、理解,实现对车辆、行人等障碍物的识 别,以及对车道线、红绿灯等交通标识的检测。自身定位(在哪里):利用全球导航卫星系统(GNSS)、惯性测量单元(IMU)、高清地图、车速传感器等获取车辆自身空间状态信息。环境状态信息以及自身状态信息为 后续车辆预测、规划等决策环节提供依据。
决策:决策环节是自动驾驶的核心,其主要功能是回答几个问题:预测(接下来会发生什么)、决策(该 做什么)、规划(怎么做)。在感知环节完成对自身精确定位和对周围环境准确理解的基础上,决策环节主要 是对接下来可能发生的情况进行准确预测,对下一步行动完成准确判断和规划,并选择合理的路径达到目标, 指导执行系统对车辆进行控制。 执行:自动驾驶系统最终要借助对车辆的控制达到自动驾驶的目的。执行环节负责将决策和规划落实为切 实的行为。执行系统控制器(如底盘控制器、动力系统控制等)接收决策系统输出的目标路径轨迹,通过一系 列结合自身属性和外界物理因素的动力学计算,转换成对油门、刹车、转向的控制,尽可能控制车辆按目标速 度和方向行驶。 完成上述 3 大任务需要车端系统、云端系统的支持,以及各类技术(如先进的整车电子电气架构、OTA、 V2X 等)的保障。完备的车端系统是自动驾驶功能实现的主要装备保障,仅靠车端系统即可实现初级和部分中 级自动驾驶功能。车端系统主要包括:感知定位传感器系统、车载智能计算平台(简称计算平台)和底盘/动力 系统。
车载智能计算平台:如同人类大脑,完成感知环节的识别融合任务以及整个决策环节。自动驾驶几乎所有 的计算都集中在计算平台。各类专用、通用芯片组成的硬件资源为计算平台提供算力保障。基于虚拟机、各类 操作系统、中间件的系统软件架构为自动驾驶算法和功能实现提供软件平台。AI 算法、滤波算法、规划算法等 基础算法库以及保障工程实现的安全、备份、通信等基础功能库组成的功能软件为差异化的应用实现提供基础 模块支持。计算平台的软硬件的差异是各厂商自动驾驶功能差异的核心所在,计算平台性能优良体现厂商自动 驾驶技术实力的高低。 底盘/动力系统:如同人类手脚,负责执行环节。底盘/动力系统包括对应的控制器和机械执行机构。底盘系 统负责实现车辆转向和制动,动力系统负责车辆驱动。对于自动驾驶汽车,执行机构电子化,以及更进一步的 线控技术是执行系统的基本技术要求。比如电子油门、电子助力转向、电子助力制动等。执行机构电子化实现 人机解耦和自动控制。比如传统的真空助力制动系统只有当驾驶员踩动制动踏板,刹车助力系统才会工作。采 用电动助力系统后,驾驶员不踩制动踏板,只要启动助力电机也能推动制动主缸,最终产生制动。
1.2 什么是车载智能计算平台?
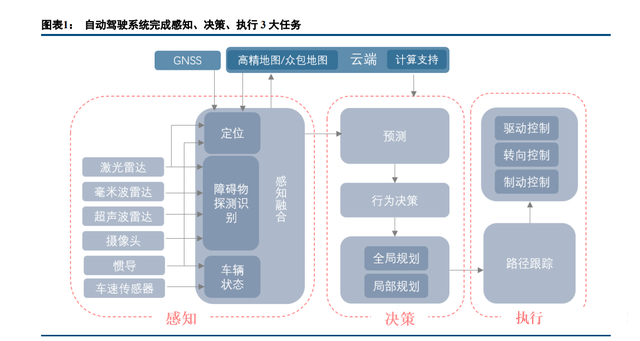
车载智能计算平台是实现高阶自动驾驶的必选方案。自动驾驶过程中需要一个强劲的“大脑”来统一实时 分析、处理海量的数据与进行复杂的逻辑运算,对计算能力的要求非常高。计算平台本质也是嵌入式系统,相 比于汽车传统控制器 ECU(比如:发动机 ECU、变速器 TCU、车身 BCM、电池 BMS、电机 MCU、整车 VCU), 其硬件和软件的复杂度更高,算力更高,功能更强。 硬件方面,汽车传统 ECU 主要采用 MCU(微控制单元,Microcontroller Unit)实现简单的计算和逻辑判断。 智能计算平台通常使用单个甚至多个集成 CPU、GPU、FPGA 或 AISC 的 SoC,可实现大量数据的并行计算和 复杂的逻辑功能。 软件方面,传统 ECU 软件架构较为简单,底层操作系统 OSEK,中间件采用 CP AUTOSAR 框架,顶层为 应用程序。部分功能简单的控制器甚至不需要使用操作系统和中间件。智能计算平台软件架构更复杂,层次更 多,自下而上包括虚拟机、操作系统(支持多类实时与非实时操作系统)、中间件、功能软件和应用软件。
1.2.1 车载智能计算平台架构
计算平台的功能实现需要丰富的硬件资源和复杂的软件支持。不同硬件资源的集成形成计算平台的硬件架 构,将复杂的软件分层化处理构成了计算平台的软件架构。
硬件架构:片内引入专用计算单元、板上集成多 SoC 自动驾驶中央计算平台的结构通常包括电路 PCB 板、散热部件和外壳。电路 PCB 板是计算平台是功能实 现的核心,即是通常所称的计算平台“硬件”。中央计算平台硬件架构可分为三层: 板级:即 PCB 板,其上集成了 SoC、I/O 接口、内存、电源模块以及其他电子器件。更高阶的自动驾驶功 能对计算平台的算力要求越来越高,考虑冗余的功能安全要求,单 SoC 设计已经无法满足要求,计算平台需要 集成多个主 SoC。 片级:即系统级芯片(SoC),主控芯片上集成了多个和多类计算单元。在传统 PC 时代,各个核心芯片都 是以独立的方式存在,比如英特尔和 AMD 的 CPU、NVIDIA 的 GPU 等。到了移动互联网时代,由于体积功耗 方面的要求,主芯片集成度大幅提升,除了 CPU 和 GPU,通常还包含了音频、多媒体、显示、安全、通信、 AI 计算等子单元。高度集成的 SoC 自然成为自动驾驶计算平台的首选。 核级:即芯片的计算单元,如 CPU、GPU、FPGA、ASIC 等。不同种类的计算单元有各自的优势,分别负 责不同任务。CPU 通用性最强,主要负责复杂逻辑运算;GPU 通用性不如 CPU,但计算能力高,适合同时处理 大量的简单计算任务,如运行深度学习算法;FPGA 和 ASIC 是专用型计算单元,针对某类运算定制,以达到最 优的性能和功耗比。这类计算单元主要用来运行如神经网络等 AI 算法。
系统软件:承上启下,实现应用软件与物理硬件分离。系统软件自下向上分为三层。 1) 虚拟机(Hypervisor):通过将虚拟化将物理硬件隐藏,实现多个操作系统共享一个芯片; 2) 操作系统内核:即狭义操作系统(如 OSEK OS、QNX、Linux)。内核提供操作系统最基本的功能, 负责管理系统的进程、内存、设备驱动程序、文件和网络系统,决定着系统的稳定性和性能; 3) 中间件:处于功能应用和操作系统之间,提供标准接口、协议,保证上层软件具有较高的移植性。 功能软件:为自动驾驶功能提供共性功能模块。其可进一步分成两层,下层为实现自动驾驶的基础模块(如 基础算法、功能安全、通信存储等),上层为自动驾驶子功能模块(如感知、定位、预测等)。 应用程序:实现具体的自动驾驶功能。开发者根据自身产品功能定义,利用功能软件层提供的基础库,设 计出具体的应用功能,比如低等级的 ADAS 辅助驾驶功能(AEB、ACC 等)、较高等级的自动驾驶功能(APA、 TJP、HWP 等)、甚至 L4 以上的自动驾驶功能。
1.2.2 车载智能计算平台怎样实现功能
车载智能计算平台开发流程
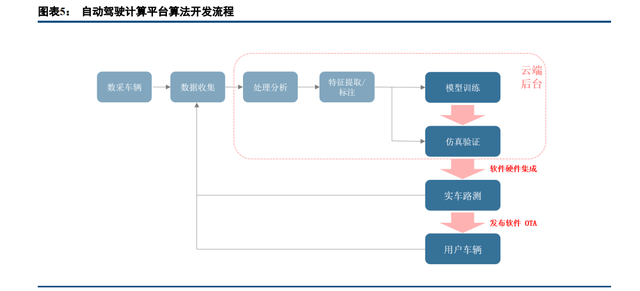
计算平台软件开发依赖大量数据验证,实现高级别的自动驾驶功能需要长期的开发周期。厂商通常为计算 平台预埋充足的硬件资源,逐步完善和解锁性能更优的功能。OTA(尤其是 FOTA)使计算平台软件迭代更新 成为可能。车载计算平台算法开发和升级通常包含以下几个步骤: 1) 数据采集。利用具有自动驾驶能力或者数据采集能力的车(要求包含 GPS、惯导、摄像头、毫米波雷 达、激光雷达等所有传感器,底盘动力为线控系统,车上有数据采集控制器),实时采集车辆看到的 各种场景,以及对应场景下车辆运行的状态。 2) 构建场景样例。将采集的数据上传到云端数据中心,数据中心端依靠人力或全自动化清洗和标注数据, 形成大量的场景。 3) 算法训练。将大量场景样例输入初始算法模型,不断调整模型参数使模型输出与目标一致。 4) 仿真验证。将训练好的模型和其他的软件算法集成,在云端的仿真器平台做模拟的仿真,验证软件算 法的准确性和可靠性。 5) 实车路测。将软件算法刷写进车载计算平台,进行实际路测。在实测中发现问题,针对性的采集特定 区域的数据,再完成算法训练优化,在进行仿真和实测。 6) OTA 更新计算平台。车辆销售后,厂商根据实际道路的数据和用户反馈,对软件算法进行升级,通过 OTA 更新用户车载计算平台软件。
车载智能计算平台工作过程 车载智能计算平台的职责是完成感知环节的识别融合任务以及整个决策环节。 1) 识别融合:摄像头、激光雷达等传感器实时采集路况信息,通过以太网传输至车载中央计算平台,感 知模块根据输入图像信息调用一系列基础算法模块对信号进行滤波、识别。这类算法程序利用中间层 提供的统一接口访问操作系统。操作系统在经过虚拟机调用 SOC 中的 GPU 或 FPGA 或 ASIC 相关资源 完成的数据处理。 2) 决策:感知模块完成处理将结果数据通过中间层传递给决策模块。同样,决策模块调用基础算法模块, 层层经过中间层、操作系统和虚拟机调用 CPU 等硬件资源完成复杂计算。决策结果即目标路径、车速 等信息再经过以太网从中央计算平台传递至底盘、动力域控制器。
1.3 车载智能计算平台供应生态
车载智能计算平台主要有三大类参与者:整车厂商、传统汽车零部件商、硬件厂商。另外还有算法方案解 决商、Robotaxi 厂商、专业系统软件商等。
1) 整车厂商:定义和开发自动驾驶功能应用。整车厂商根据市场需求和产品定位,设计自动驾驶功能。 大部分整车厂商主要关注车载智能计算平台应用软件的开发。各家整车厂商自动驾驶技术水平差异显 著。特斯拉是自动驾驶汽车的领导者,研发能力覆盖应用软件、功能软件甚至底层系统软件,同时能 够根据自身算法需求自研专用 AI 芯片。为打造差异竞争,造车新势力较传统厂商在汽车智能化领域布 局节奏更快。小鹏汽车软件自研能力强,包括视觉感知、激光雷达感知、高精度定位规划等算法已经 实现全栈自研。蔚来汽车和理想汽车也搭建了强大的自动驾驶研发团队。传统整车厂商部件节奏较慢, 主要依赖供应商提供解决方案。比如吉利汽车极氪 001 采用 Mobileye 的软硬件方案,北汽蓝谷采用华 为的软硬件方案,上汽知己算法开发由 Momenta 提供支持。未来,整车厂商首先立足应用层软件开发, 进而向下延申提升功能算法、系统软件架构的自研能力,甚至设计部分专用芯片,达到软硬一体化设 计能力。
2) 传统零部件 Tier1:布局中间件为主。在传统汽车控制器中,如大陆、博世等零部件商为整车厂商提供 硬件(向芯片商采购)和软件平台(基于 CP AUTOSAR 的操作系统和中间件),支持整车厂商应用开 发。对于车载智能计算平台,汽车零部件厂商继续发挥车规级开发能力的优势,为计算平台提供满足 车规要求的中间件。未来,汽车零部件商将向上层功能软件和应用解决方案布局,同时向下部件操作 系统甚至硬件层。
3) 硬件厂商:为计算平台提供各类芯片。传统汽车控制器采用 MCU,主要芯片供应商是英飞凌、IT 和 NXP。他们在汽车芯片领域深耕,为博世、大陆提供芯片用于开发 ECU。自动驾驶对硬件算力要求更 高,GPU 以及 FPGA、ASIC 等高性能专用芯片开始应用到汽车。如英伟达、高通、英特尔等消费产品 芯片供应商进入汽车供应链。基于高壁垒的芯片及配套系统软件,实力强的芯片商将能力圈向应用层 拓展。如 Mobileye、华为可提供软硬件的全套解决方案。
二、硬件结构:集成化是趋势,开放性是核心
2.1 核级:硬件最底层,自动驾驶促进专用性提升
2.1.1 是什么:硬件层面底层架构
L2 以上自动驾驶需要处理雷达及相机等传感器输入的数据,数据量指数级增长,因此需要基于深度学习的 AI 算法实现数据处理能力的飞跃。传统 ADAS 层面处理器计算单元 CPU 已无法满足 AI 算法需求,目前已开发 多种架构计算单元,主要分为通用型(CPU、GPU)和专用型(FPGA、ASIC)两大类。
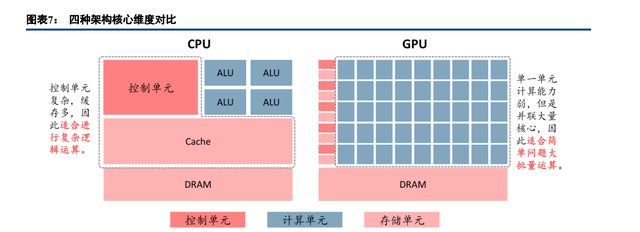
通用芯片:CPU、GPU
CPU(Central Processing Unit,中央处理器):计算机系统的运算和控制核心,是信息处理、程序运行的 最终执行单元。优点:CPU 有大量的缓存和复杂的逻辑控制单元,非常擅长逻辑控制、串行的运算。缺点:不 擅长复杂算法运算和处理并行重复的操作。类比来看,CPU 就像是教授,复杂问题都可以解决,但是让他做 100 道小学算术题也需要一定时间。 GPU(Graphics Processing Unit,图像处理器):也称显示核心,是一种做图像和图形相关运算工作的微 处理器。优点:核心数非常多,可以支撑大量数据的多核并行计算。缺点:管理控制能力弱,功耗高。类比来 看,GPU 就像 100 个小学生,虽然复杂问题无法解决,但是同时做 100 道小学算术题却可以很快完成。
专用芯片:FPGA、ASIC
FPGA(Field Programmable Gate Array,现场可编程逻辑门阵列):是一个可编程芯片,用户可以自定 义芯片内部的电路连接来实现特定功能,常用于算法训练优化。优点:可以无限次编程,延时性比较低,实时 性最强,灵活性最高。缺点:开发难度大、价格比较昂贵。 ASIC(Application Specific Integrated Circuit,特殊应用集成电路):ASIC 已经制作完成并且只搭载一种 算法和形成一种用途,一旦设定制造完成,内部电路以及算法就无法改变。优点:体积小,功耗低,性能以及 效率高,量产成本非常低。缺点:首次“开模”成本高,灵活性不足。代表性神经网络处理器包括谷歌公司研 发的张量处理器(Tensor Processing Unit, TPU),以及特斯拉自研的神经网络处理器(Neural Network Processing Unit,NPU)等。
从计算能力、通信延迟、成本三个核心维度对四种架构进行比较: 计算能力:ASIC> FPGA >GPU > CPU。CPU 和 GPU 作为通用芯片,适用范围较广,由于 GPU 集成大量 内核,因此并行计算能力高 CPU 近百倍。但是通用芯片势必会造成过程冗余,导致 AI 算力浪费,因此算力显 著低于专用芯片。专用芯片包含 ASIC 和 FPGA,其中 ASIC 专用性更强,针对单一算法和功能优化最佳,因此 算力强于 FPGA。 通信延迟:ASIC≈ FPGA FPGA >GPU ≈ CPU。专用芯片开发语言难度 大,适用性较差,因此开发成本高于通用芯片。其中 ASIC 由于无法编程,对算法以及硬件的封装程度更高, 因此开发成本高于 FPGA。量产成本:FPGA >ASIC> GPU ≈ CPU。由于 ASIC 是一次封装完成的芯片,后续量 产标准化程度高,量产成本很容易下降,而 FPGA 每一片都要进行调试,因此量产成本 ASIC 占优。
2.1.2 趋势:由通用走向专用
自动驾驶芯片架构的技术发展趋势主要考虑以下四个维度: 第一点,算力要求高。由于处理的传感器信息需要大量冗余,对终端算力要求极高,并且车速越快,对计 算能力要求越高; 第二点,终端计算的实时性要求极高。任何超出一定范围的延迟,都有可能造成事故,因此终端会负责自动驾驶的核心计算和决策功能; 第三点,能效要求高。否则降低车辆续航,影响驾驶体验。高能耗同时带来的热量也会降低系统稳定性。 例如支持 L4 的 NVIDIA Drive Pegasus 功耗为 460W,只能应用于小规模的测试车; 第四点,可靠性要求高。真正满足车规的自动驾驶芯片需要在严寒酷暑、刮风下雨或长时间运行等恶劣条 件下,都有稳定的计算表现。
目前自动驾驶硬件架构方案主要为 GPU+FPGA 异构。GPU 适用于单一指令的并行计算,主要负责并行处 理数据;FPGA 与之相反,适用于多指令、单数据流,主要负责训练优化算法。当前阶段还处于算法快速迭代 时期,需要依托 FPGA 可编程性,进行开发过程不断试错。因此结合两者优势,形成当下主流 GPU+FPGA 的异 构解决方案。 未来自动驾驶芯片的核心架构是 ASIC。当前阶段 FPGA 的优势是算法快速迭代背景下开发的便利性,当 自动驾驶汽车量产,形成了较为稳定的算法后,ASIC 的量产低成本、性能高、功耗低等优势就可以体现。类比 来看,FPGA 就是乐高搭建模型,可以低成本快速测试性能,而 ASIC 是开模具,虽然首次开模成本高,但是后 续量产成本低且性能更好。因此,我们认为短期内还是会以 GPU+FPGA 异构为主,量产后会逐渐向 ASIC 迁移。
2.1.3 格局:GPU、FPGA 寡头垄断,ASIC 仍是蓝海
总体来看,传统 CPU 行业龙头是英特尔和高通,GPU 行业龙头是英伟达,FPGA 行业龙头赛灵思,只有 ASIC 领域暂未形成明显的龙头。

2.1.3.1 GPU
全球 GPU 市场已经进入了寡头垄断的格局。在传统 GPU 市场中,排名前三的英伟达、AMD、英特尔的营 收几乎可以代表整个 GPU 行业收入。其中,2019 年英伟达的收入占 56%、AMD 占 26%、英特尔占 18%,英伟 达占据绝对的行业垄断地位。
2.1.3.2 FPGA
目前的 FPGA 市场由海外巨头赛灵思和 Altera 主导,两者共同占有 80%的市场份额。2015 年 Intel 决定以 167 亿美元收购 FPGA 生产商 Altera,IBM 也和赛灵思联合宣布开展一项多年战略协作,打造更高性能的数据 中心应用,IT 大厂的介入也说明了 FPGA 在 AI 领域的重要地位。 国产 FPGA 起步较晚,技术水平落后 2-3 代。FPGA 细分领域具有技术壁垒高、资金投入大的特点,国外 头部企业历经多年发展形成了技术和专利方面的高壁垒,造成国内企业发展受限,目前只能从低端产品切入, 通过技术升级不断向高端产品演化。因此,部分厂商弱化芯片制造业务,主攻深度学习算法解决方案,为 FPGA 提供更优化的算法结构,提升芯片性能,代表公司深鉴科技 2018 年以 3 亿美金的价格被赛灵思收购。
2.1.3.3 ASIC
目前国外主要以谷歌为主导,国内主要是寒武纪。人工智能领域的 ASIC 专用芯片仍是一片蓝海,尚未出 现足以垄断市场的巨头公司。 在 ASIC 芯片领域,国内厂商已经取得了一定成绩。以比特大陆、嘉楠耘智为代表的矿机厂商采用的 ASIC 芯片已经达到了 7nm 制程,在国际中处于较先进地位。寒武纪科技推出的寒武纪 1A 处理器(Cambricon-1A) 是世界首款商用深度学习专用处理器,面向智能手机、安防监控、可穿戴设备、无人机和智能驾驶等各类终端 设备,在运行主流智能算法时性能功耗比全面超越 CPU 和 GPU。
2.2 片级:系统级芯片,集成化趋势显著
2.2.1 是什么:片上芯片,多个计算单元的集合
定义:系统级芯片(System on Chip, SoC)是指多个计算单元集成到一块芯片上,从而实现功能集成的设 计方案。传统汽车芯片为微控制器(Micro Control Unit, MCU),又称单片机,简单来说是就是将简化版 CPU 与功能部件集成在一个芯片上,形成“芯片级芯片”,通常只能完成单一信号控制,实现单一功能。随着自动 驾驶级别提升,需要实现的功能增多,计算能力要求更高,MCU 已不满足需求,因此将多个计算单元集成到一 块芯片上形成“系统级芯片”。
结构:SoC=n1*CPU+n2*GPU +n3*FPGA+n4*ASIC+其他功能单元(ISP、VP 等)。以英伟达 Xavier 为例 对 SoC 架构进行说明。通常 SoC 会集成计算单元和功能单元两部分,计算单元包含通用芯片 CPU 和 GPU,总 计占据约 1/2 的面积,部分计算单元包含专用芯片 FPGA 和 ASIC,面积占比约为 1/20。功能单元主要包含数据 存储和数据预处理两部分,其中数据存储和调用主要通过内存实现,内存就像局部地区建立的一个仓库;数据 预处理包含用于图像信号预处理的 ISP 芯片、视频解码器 VP 等器件。
2.2.2 趋势:集成化、高算力、先进制程、开放化
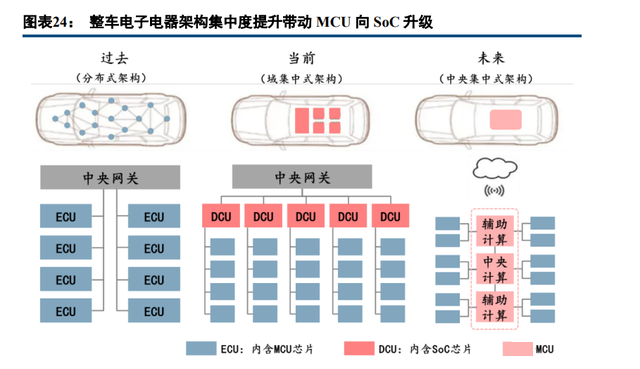
自动驾驶芯片是硬件部分核心,也是自动驾驶方案竞争的制高点,目前技术快速迭代背景下存在三点趋势: 第一点,集成化,MCU 加速走向 SoC。伴随整车电子 E/E 架构集中度提升(分布式→域集中式→中央集 中式),起决策作用的单元由 ECU→DCU→中央计算平台,ECU 数量大幅精简,因此其内含 MCU 芯片数量下 降,加速 MCU 向集成度更高的 SoC 升级。
第二点,高算力,同时兼顾算力功耗比。硬件层面,提升单车智能化程度、实现高级别自动驾驶的核心是 提升系统级芯片算力,因此提升芯片算力仍然是厂商研发考虑的第一要素。目前阶段,芯片算力可类比智能手 机发展过程的相机像素,虽然拍照效果受算法、相机像素、传感器等多方面因素影响,但是像素提升带给消费 者的感知最强烈,消费者也更愿意支付高像素带来的溢价。同理,自动驾驶芯片算力也具有类似的消费属性, 因此短期来看,厂商势必会通过提高芯片算力来抢占市场高点。
第三点,先进制程,5nm/7nm 是未来趋势。晶体管是芯片的最小组成单元,可以把晶体管比作水池,水流 从源极流入漏极,栅极就相当于两个水池之间的水管,栅极的最小宽度(栅长)就是制程。水管越短,水流越 快完成水池间运输,水流在水管内的摩擦损耗越小。制程类比水管长度,越宽电流通过时的损耗越大,外部表 现就是器件发热和功耗增大。因此制程减小是技术发展趋势。
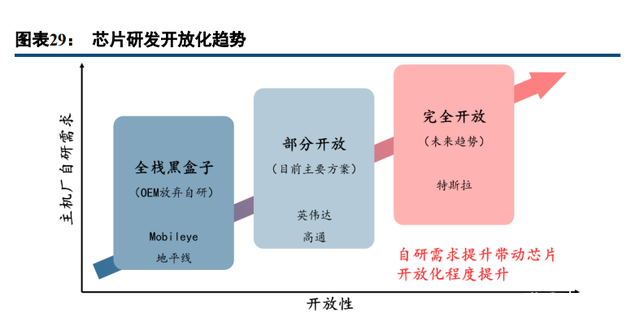
第四点,开放化,OEM 对功能拓展性的需求促进了芯片开放化趋势。主机厂需要在硬件基础上进行功能 开发,因此底层芯片开放性越高,越有利于主机厂进行功能拓展。在这背景下,自研能力较强的主机厂(如特 斯拉)选择了自研芯片,实现了底层完全开放;而像英伟达等厂商推出的芯片开放性也不断增强,供主机厂修 改部分不断扩充,因此得到更多主机厂青睐;相反的,开放性较差的厂商(Mobileye、地平线)则逐渐被主机 厂抛弃,只能在完全没有自研意愿的主机厂中寻求剩余机会。
2.2.3 格局:L2 以上自动驾驶消费电子领域巨头弯道超车
四类核心玩家:传统汽车芯片厂商(瑞萨、Mobileye 等)、消费电子芯片厂商(英伟达、高通等)、研发 能力较强的主机厂(特斯拉)及科技公司(华为、地平线、黑芝麻)。传统汽车芯片厂商具备汽车产业链优势, 但是芯片功能相对单一,采取基于 ADAS 不断补充功能实现更高级别自动驾驶的“自下而上”的策略;随着 L2+ 高级别自动驾驶逐渐落地,传统单一功能汽车芯片已无法满足要求,具备较强 AI 计算优势的消费电子芯片厂商 快速切入,凭借“自上而下”的策略实现弯道超车。此外,具备较强研发能力的主机厂(特斯拉)及部分科技 公司(华为、地平线、黑芝麻)也是主要玩家。
各厂商能力:第一梯队是芯片巨头英伟达和高通,一流芯片算力基本在 100TOPS 以上,算力功耗比 3.0 以 上。英伟达新一代 Orin 单芯片算力 254TOPS,相比其他厂商普遍高 4-10 倍。具体来看,英伟达相对高通功耗 控制较差,算力功耗比相对偏低。第二梯队是特斯拉和黑芝麻,与第一梯队芯片工艺能力还有较大差距,单芯 片算力 70TOPS 左右。第三梯队是 Mobileye 和地平线,单芯片算力普遍比较低(25TOPS 以下),仅能实现 L2 及以下功能。华为相对特殊,昇腾 910 芯片算力高达 640TOPS,功耗 310W,虽然单纯算力达到世界顶尖水平, 但是整体能效控制较差,算力功耗比仅为 2.1。总体来看,芯片目前处于技术快速迭代期,算力不断提升,厂商 纷纷加入算力游戏,开展高算力芯片军备竞赛。
2.2.3.1 英伟达:起步早、势头猛、布局快
起步早:入局已有六年之久,保持两年更新频率。智能驾驶领域英伟达前后已推出 4 代芯片(其他厂商普 遍 1-2 代),2015 年最早推出 Parker 芯片,面向 ADAS 应用,不具备深度学习功能。2017 年推出首款自动驾驶 AI 芯片 Xavier,可以满足 L2/3 级应用,2019 年推出高算力芯片 Orin,满足 L4/5 级应用。计划 2021 年推出下 一代超高算力芯片 Atlan。
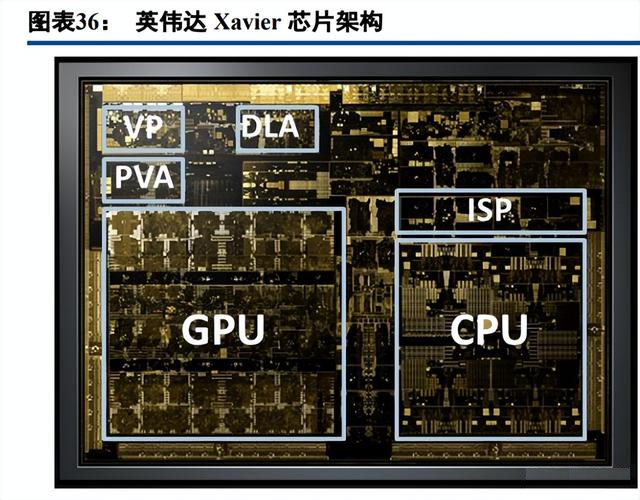
具体历代 AI 芯片来看,英伟达均采用 CPU+GPU+ASIC 的技术路线。Xavier 芯片除集成 GPU、CPU、ISP 等标准组件外,创新集成 DLA。DLA 是 ASIC 架构专用引擎,可以高效处理深度学习算法,使单芯片算力由 20TOPS提升至30TOPS。DLA面积仅为GPU的1/8,然而贡献算力是GPU的1/2(DLA=10TOPS,GPU=20TOPS), 因此 DLA 可以大幅提升芯片算力功耗比,也印证了 ASIC 架构的优越性。Xavier 芯片参数:三星 12nm 工艺, 算力 30TOPS,功耗 30W,算力功耗比 1.0。Orin 架构与 Xavier 基本相同,采用三星 8nm 工艺,算力 254TOPS, 功耗 65W,算力功耗比 3.9。
Atlan 是 L5 终极解决方案:2021 年 4 月 GTC 上英伟达发布下一代数据中心级别 SoC,命名为 Atlan,首次 实现单芯片算力超过 1000TOPS,面向 2025 年 L5 自动驾驶应用。创新点在于英伟达自研新一代 CPU(Grace), 用于大规模人工智能和高性能计算应用,计划 2023 年投产。首次集成 DPU(Bluefield-3),实现了 10 倍的性 能飞跃,能够替代 300 个 CPU 核,以 400Gbps 的速率,对网络流量进行保护、卸载和加速。我们认为,英伟达 宣传高算力 Atlan 更多目的是为拉对手军备竞赛,压迫对手跟进算力游戏,以此凸显自身芯片研发能力优势, Orin 还是其未来五年内主要产品。
2.2.3.2 高通:起步晚,实力强,扩展性
起步晚:由于收购恩智浦失败,高通在智能驾驶领域入局较晚。与英特尔收购 Mobileye 类似,高通也想通 过收购恩智浦切入 ADAS,从而往更高级别自动驾驶延伸。2016 年 10 月,高通宣布收购恩智浦,收购价为 470 亿美元。2018 年 7 月,由于政策原因,高通宣布放弃收购恩智浦。本次收购失败严重拖累了高通在自动驾驶领 域的布局,直接导致高通入局相对英伟达晚了三年,目前也仅发布了一代芯片。
扩展性:依托智能座舱同源性向自动驾驶扩展。高通在智能座舱领域一骑绝尘,市场份额高达 70%,国外 最紧密合作者是美国通用,国内是长城 WEY。智能座舱芯片是前哨战,自动驾驶芯片才是制高点,由于智能座 舱和自动驾驶同源性较强,厂商为降低开发费用和周期,会选用适配性较好的同一架构芯片,因此高通可以凭 借智能座舱领域优势快速向自动驾驶扩展。代表案例:长城 WEY“咖啡智能”平台已采用高通自动驾驶芯片。 优劣势分析:高通优势在于强大的生产制造能力,凭借多年智能手机芯片霸主地位以及智能座舱领域垄断 优势,对于量产落地的功耗控制能力较强,维持高算力的同时算力功耗比通常在 4 以上;同时,高通已布置了 非常多的芯片产线,可以通过多产线去摊薄研发成本,进一步取得自动驾驶芯片成本优势。劣势主要还是入场 太晚,在近两年各厂商“跑马圈地”的情况下,没有形成大规模的客户群体。
2.2.3.3 特斯拉:逐步自研,软带动硬
逐步自研:自研新一代 FSD3.0 自动驾驶 SoC。特斯拉一直以来都是自动驾驶领域的领路人,软件部分视 觉算法能力全球领先。硬件部分,早期特斯拉基于 Mobileye EyeQ4 芯片实现 ADAS 级别应用,2015 年后转用 英伟达 Xavier 芯片开发 L2 级别自动驾驶,然而外采方案下芯片核心架构在芯片厂商手中,特斯拉自主开发受 限,难以实现软硬件充分适配,因此特斯拉决定自研芯片 SoC,并计划于 2021 年推出最新一代 FSD3.0。 FSD3.0 采用了 CPU+GPU+ASIC 架构。FSD3.0 中特斯拉核心自研部分是 NPU,NPU 是 ASIC 架构的处理 器,适用于进行深度学习计算。NPU 中间的核心组件是乘加累计器(Multiply Accumulate Cell, MAC),可以提 供 9216(96*96)个计算单元,每个单元可以完成 8 位的乘积运算和 32 位的加法运算,所以一个时钟周期可以 完成 9216*2=18432 次的 int8 的操作, NPU 的频率是 2GHz,其运算能力 2GHz*18432/1000=36.86TOPs(int8)。 自研芯片采用三星 14nm 工艺,总体表现为算力 72TOPS,功耗 36W,算力功耗比 2.0。
2.2.3.4 Mobileye:起点高,进步慢,被替换
起点高:Mobileye 是 ADAS 芯片绝对龙头。Mobileye 的 EyeQ 系列芯片在 2004 年就开始研发,2007 年 发布的第一代 EyeQ1 芯片是较早应用于自动驾驶的 AI 芯片之一(仅实现辅助驾驶功能)。目前 ADAS 领域 年出货量近 2000 万颗芯片,市占率高达 60%。
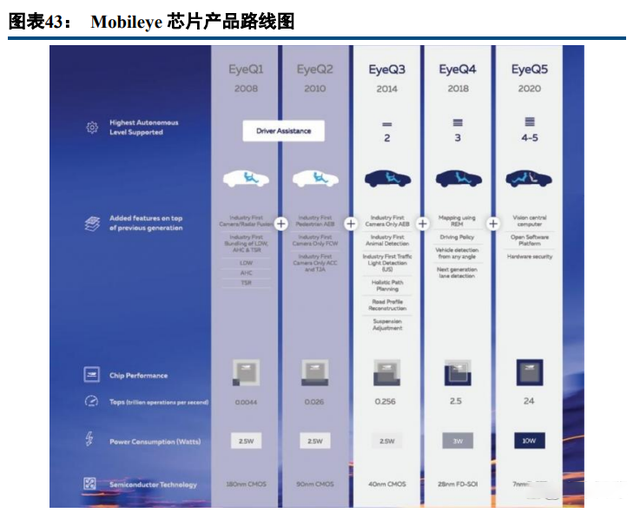
进步慢:Mobileye 业务模式是向 OEM 提供定制化 ADAS 和自动驾驶方案,然而 2015 年,Mobileye 发布了 一款新的芯片 EyeQ4,该芯片建立在多核架构的基础上,用于在 ADAS 中进行计算机视觉处理。区别于主流 CPU 架构(ARM、X86),EyeQ4 采用了小众的多 MIPS 处理器,导致其通用性和可开发性较差。EyeQ4 算力 2.5 TOPS, 功耗仅 3W,相比 EyeQ3 算力提升近 10 倍,功耗仅增加 0.5W,说明 Mobileye 优势在于功耗控制,但是整体算 力还是偏低。
优劣势分析:优势在于成本低,全栈黑盒子方案降低 OEM 研发开销;此外,算法与芯片都是自主研发, 适配性好,芯片开发度高。总体来看和特斯拉特点很像,Mobileye 就像不造车的特斯拉,但是硬件能力比特斯 拉强。劣势在于全栈黑盒可开发性较差,无法满足有自研需求的 OEM;同时,MIPS 架构 CPU 通用性较差,难 以形成良好的软件生态。
2.2.3.5 华为:起步晚、布局广、受制裁
起步晚:华为 2018 年才发布第一款 AI 处理器昇腾 310,算力 16 TOPS,功耗 8W,算力功耗比达 2.0。 昇腾 910 是目前单芯片算力最强的一款芯片,它是一款面向服务器的 AI 芯片,对标英伟达、谷歌同类产品, 算力高达 640 TOPS,功耗为 310W,能效比达 2.1。

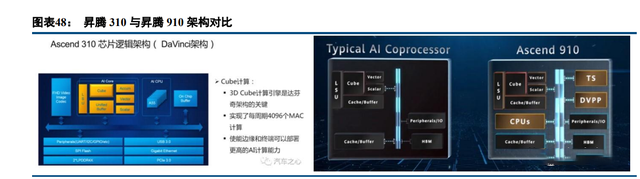
昇腾 310 与 910 都采用了达芬奇架构。不同于传统的支持通用计算的 CPU 和 GPU,也不同于专用于某种 特定算法的专用芯片 ASIC,达芬奇架构本质上是为了适应某个特定领域中的常见的应用和算法,通常称之为“特 定域架构”。具体来说,达芬奇架构采用 3D Cube 针对矩阵运算做加速,每个 AI Core 可以在一个时钟周期内 实现 4096 个 MAC 操作,相比传统的 CPU 和 GPU 实现数量级的提升,从而大幅提升单位功耗下的 AI 算力。 同时,达芬奇架构还集成了向量、标量、硬件加速器等多种计算单元,同时支持多种精度计算,能够实现云、 到边缘、到端、到物联网端的全场景覆盖。最后,达芬奇架构具有统一性,在面对云端、边缘侧、端侧等全场 景应用开发时,只需要进行一次算子开发和调试,就可以应用于包括麒麟芯片在内的不同平台,大幅降低了迁 移成本。
基于昇腾 910,华为开发了:1)Atlas 800 训练服务器,具有最强算力密度、超高能效与高速网络带宽等特 点,可以广泛应用于深度学习模型开发和训练,适用于智慧城市、智慧医疗、天文探索、石油勘探等需要大算 力的行业领域。2)Atlas 900 AI 集群,由数千颗昇腾 910 组成,总算力达到 256P~1024P FLOPS @FP16,相当 于 50 万台 PC 的计算能力,可以让人类更高效的探索宇宙奥秘、预测天气、勘探石油,加速自动驾驶的商用进 程。 昇腾芯片因其独特的达芬奇架构,可以在云、到边缘、到端、到物联网端等实现全场景覆盖,不仅仅是在 车端,在智慧城市、交通、金融、能源、园区管理等领域昇腾芯片都可以提供服务,这意味着华为可以凭借其 庞大的客户群体摊薄研发费用。
 受制裁:由于受到美国制裁,华为最大的问题就是供应链安全,短期内可以依靠他们已经囤积的一些芯片 去支撑,等消耗完库存后,会被迫切换到 28 nm 工艺,这种在能效比上会很差。所以长期来看,如果国内先进 芯片生产、先进材料,EDA 软件上不来,美国短期内又不会解除对他的制裁,那么华为发展高阶高算力的自动 驾驶就存在很大的困难。 优劣势分析。优势:1)成本低,降低 OEM 研发开销;2)除了 ARM CPU 可能要买 ARM 公司的授权之外, 其它几种硬件引擎都可以自研,研发能力很强;3)在云、边缘、端、物联网端都有布局,业界布局最广。劣势: 1)芯片能效相比高通英伟达还有一定差距;2)受制裁,芯片生产可能受限。
受制裁:由于受到美国制裁,华为最大的问题就是供应链安全,短期内可以依靠他们已经囤积的一些芯片 去支撑,等消耗完库存后,会被迫切换到 28 nm 工艺,这种在能效比上会很差。所以长期来看,如果国内先进 芯片生产、先进材料,EDA 软件上不来,美国短期内又不会解除对他的制裁,那么华为发展高阶高算力的自动 驾驶就存在很大的困难。 优劣势分析。优势:1)成本低,降低 OEM 研发开销;2)除了 ARM CPU 可能要买 ARM 公司的授权之外, 其它几种硬件引擎都可以自研,研发能力很强;3)在云、边缘、端、物联网端都有布局,业界布局最广。劣势: 1)芯片能效相比高通英伟达还有一定差距;2)受制裁,芯片生产可能受限。
2.2.3.6 黑芝麻:能效高、潜力强
能效高:黑芝麻目前主要有三款芯片,A500、A1000L、A1000,在芯片能效比上黑芝麻达到了世界顶级水 准。华山一号 A500 在 2019 年 8 月发布,算力 5-10 TOPS,功耗 2W,使用台积电 28nm 工艺。A500 内部的 ISP、 视觉处理加速引擎、Ultra DL AI 加速引擎等内核均为黑芝麻自主设计,而像 CPU、部分 DSP 等内核则使用了供 应商的 IP。华山二号 A1000 在 2020 年 6 月发布,算力 40–70 TOPS,相应功耗为 8 W,能效比超过 6 TOPS/W。 A1000 内置了 8 颗 CPU 核心,包含 DSP 数字信号处理和硬件加速器,使用台积电 16nm 工艺。
目前黑芝麻在与中国一汽合作落地 A1000,与上汽合作落地 A500。 优劣势:专注于 SoC 芯片研发,芯片能力较强,但与高通、英伟达、华为没法比,在国内自动驾驶芯片上 仅次于华为,但是与 Tier1、OEM 的合作不足。2021 年开始与国汽智控合作,进行计算平台与软件算法的开发, 在软件上布局很晚,能力较弱。
2.2.3.7 地平线:循序渐进、开放性
循序渐进:地平线一步一个脚印,采取循序渐进的自动驾驶产业化路线,芯片算力逐年提高的同时,能效 比也在稳步提升,这主要得益于地平线提供一整套芯片及配套软件工具链+算法方案。在 SoC 芯片方面,地平 线目前量产的主要有征程 1.0、征程 2.0 和征程 3.0。
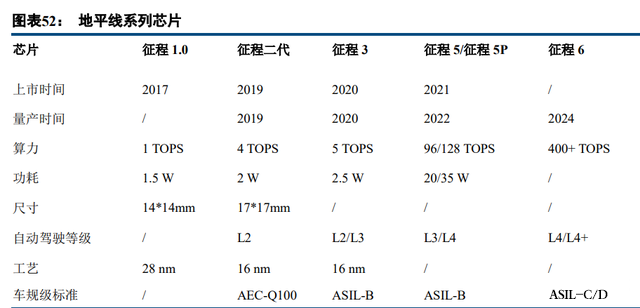
开放性:自研视觉算法+AI 开源工具链,赋能车厂 ADAS 能力。地平线一直面向深度学习这种新一代 AI 技术,相对没什么包袱,能更加开放。征程二代芯片可以支持车企开发 ADAS,前向视觉感知计算可以支持很 多差异化功能,如车辆、行人、车道线检测、测距测速等,车企也可以把芯片用于汽车座舱的智能交互,如语 音识别、眼球追踪。此外,地平线提供工具链和算法参考模型,从而车企可以自由定义产品。 地平线在自动驾驶领域的布局相当广泛。地平线 J2 已经搭载在长安汽车 UNI-T、上汽智己、奇瑞新能源蚂 蚁上,J3 搭载在赢彻科技自动驾驶卡车上,同时与广汽合作开发广汽版 J3。与大陆集团在 ADAS 和高等级自动 驾驶领域深度合作,与豪威、斑马智行等合作布局智能座舱领域,与易图通合作布局众包高精度地图领域,与 大唐移动在 5G+AI 面向车路协同智能网联展开合作。 总地来看,劣势:SoC 芯片算力较差;优势:开放的商业模式,软件能力很强,AI 算法能力一流,自动驾 驶领域布局广泛,与 Tier1、OEM 的合作广泛。
2.3 板级:域控制器,当前域融合,未来中央化
2.3.1 是什么:硬件层面总体单元
定义:域控制器是自动驾驶计算平台硬件层面的总体单元。域控制器(Domain Control Unit, DCU)的概念 最早是由以博世、大陆、德尔福为首的 Tier1 提出,为解决信息安全以及 ECU 瓶颈问题。根据汽车电子部件功 能将整车划分为动力总成,车辆安全,车身电子,智能座舱和智能驾驶等不同域,利用处理能力更强的多核 CPU/GPU 芯片相对集中的去控制每个域,以取代目前的分布式汽车电子电气架构(EEA),形成域集中式架构。 结构:DCU=n*SoC+接口+内存。从现有控制器硬件架构看多颗/多核芯片以及冗余架构是域控制器设计主 流设计,核心包括 SoC、I/O 接口以及内存。其中 SoC 主要负责提供决策,数量根据功能而定;I/O 接口主要负 责输入多传感器感知信息,比如摄像头、毫米波雷达、激光雷达等,通过后融合模式将感知信息直接输入域控 制器,以及将控制信号输出给相应执行器件;内存主要负责提供数据暂时存储、传输等功能。
2.3.2 趋势:域集中向域融合转化
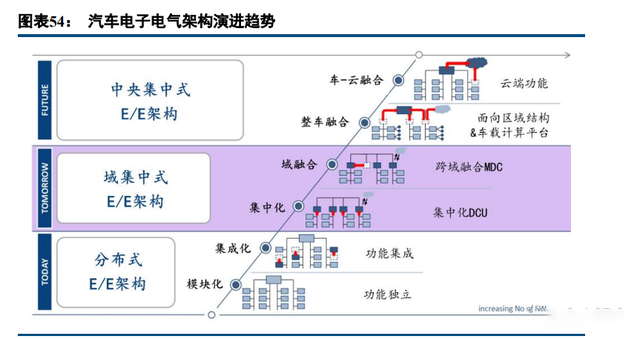
汽车电子电气架构由分布式向域集中式转化: 目前,主机厂正在应用第一类分布式 E/E 架构,分为模块化和集成化两个阶段。模块化阶段:每个功能具 备独立 ECU;集成化阶段:架构设计趋向功能集成,多个 ECU 之间进行融合。 之后,主机厂将采用第二类域集中式 E/E 架构,分为集中化和域融合两个阶段。集中化阶段:开始出现域 控制器 DCU,实现部分功能集成,融合部分 ECU;域融合阶段:开始出现跨域中心控制器 MDC,特斯拉 Model 3 是代表车型。 未来,主机厂将采用第三类中央集中式 E/E 架构,分为车载计算平台和车-云计算两个阶段。车载计算平台 阶段:采用的是车载平台和区域导向架构;车-云阶段:车辆的决策阶段在云端完成。
 MDC 优势:1)能够将感知与决策分开,传感器与 ECU 不再是一一对应的关系。对于 OEM,有 MDC 之 后,可以随意更换传感器的供货商。2)MDC 平台本身的可扩展性,MDC 所能够对接的传感器类型与数目并不 固定,可以根据 OEM 的需求对应开发。
MDC 优势:1)能够将感知与决策分开,传感器与 ECU 不再是一一对应的关系。对于 OEM,有 MDC 之 后,可以随意更换传感器的供货商。2)MDC 平台本身的可扩展性,MDC 所能够对接的传感器类型与数目并不 固定,可以根据 OEM 的需求对应开发。
2.3.3 格局:芯片厂向上拓展,主机厂向下挤压
三类主要玩家:芯片厂、传统 Tier1、主机厂。 第一类,芯片厂。由于域控制器的核心部件是 SoC,因此主要芯片厂商依靠芯片制造能力向域控制器拓展,通过收购、合作等方式快速切入 DCU 赛道,通常是同期推出新一代 SoC 与相应域控制器。代表公司包括英伟 达、高通、Mobileye、华为、地平线等。 第二类,传统 Tier1。传统汽车半导体行业中,芯片厂商扮演的是 Tier2 的角色,通常需要 Tier1 对芯片进 行进一步开发,以实现主机厂具体车型的适配。自动驾驶阶段,该模式依然在延续,代表公司包括:德赛西威、 德尔福、采埃孚等。 第三类,主机厂。主机厂外采域控制器存在算力开发不足、功能实现有限的问题,因此,主机厂希望通过 自研硬件,打通软硬件壁垒,实现数据闭环和全栈开发。代表公司包括特斯拉等。
格局变动驱动力:域控制器架构。早期 ADAS 功能相对单一,因此厂家会选择一个传感器(雷达或摄像头) 作为主控制器,接收另一个传感器的数据进行统一计算。2015 年英伟达为特斯拉推出了 Drive PX 系列自动驾驶 DCU,结合深度学习技术打造 L2+自动驾驶。为了适配深度学习算法,特斯拉进行了硬件架构革新,从雷达、 摄像头分别计算并融合(前融合),跨入到自动驾驶域控制器(后融合)。特斯拉基于英伟达的 Drive PX 芯片 研发了自动驾驶域控制器,早期仍然选用 Mobileye 感知系统,但同时额外安装了自己的摄像头来收集道路数据。 工作时,感知系统会将感知结果输出到特斯拉的域控制器中,域控制器对感知结果进行融合计算,给出决策。 这一步里,特斯拉相当于将感知部分交给供应商来做,自己完成最后的决策算法。目前宝马、通用、福特等大 型车企也都采用该方案。
各厂商能力:高通、英伟达都采取高中低配去打 L2-L5 市场,策略很相近。以英伟达 Orin 平台为例:L2 及以下通过单个 Orin 实现,L3 通过 2 个 Orin,L4-L5 通过 2Orin+2GPU。华为、特斯拉、黑芝麻目前都是双芯 片平台,通常瞄准 L3 级别应用场景。蔚来 ADAM 平台采用 4Orin 芯片堆料的策略,表观算力很高,但是算法 优化技术上难以跟进,芯片性能很难完全发挥,造成算力和功耗的浪费。总体来看,高级别自动驾驶域控制器 方案尚不明确,技术上以兼具高算力和低功耗的芯片和 GPU 的搭配使用为主。
2.3.3.1 英伟达
凭借 GPU 垄断优势,英伟达布局智能驾驶领域较早。2017 年推出的 Drive PX Xavier 和 Drive PX Pegasus平台,分别采用 1 个 Xavier 芯片和 2Xavier+2GPU 配置,算力分别达到 30TOPS 和 320TOPS,适用于 L2-L4; 2019 年推出的 Drive AGX Orin 平台算力高达 2000TOPS,主要面向 L5 级别自动驾驶。
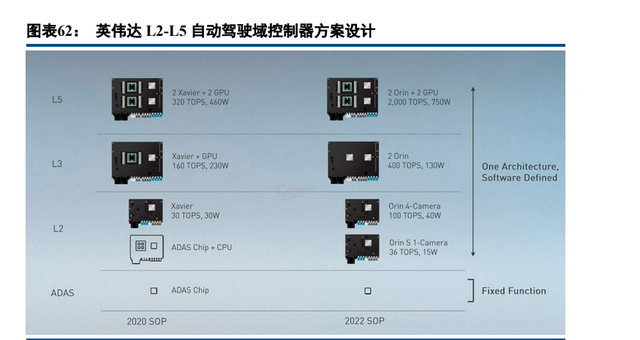
Drive PX Pegasus 可用于 L5 级自动驾驶:2017 年 10 月公布的 Drive PX Pegasus 平台可用于无方向盘、无刹 车踏板、无司机的 robo-bus 或 robo-taxi 之上。性能:2Xavier+2GPU,320TOPS,500W。劣势:功耗过高,算 力功耗比仅为 0.6。 Drive AGX Orin 是下一代域控制器:DRIVE AGX Orin 是一个软件定义的平台,旨在实现从 l2-l5 全自动驾 驶汽车的架构兼容平台,使 OEM 能够开发大规模和复杂的软件产品系列。由于 Orin 和 Xavier 都可以通过开放 的 CUDA 和 TensorRT 进行编程,开发者可以在多代产品中利用他们的投资。性能参数:2Orin+2GPU,2000TOPs, 700W。计划进度:2019 年 12 月发布,2021 主机厂适配,2022 量产车搭载。
2.3.3.2 高通
高通与英伟达类似采用两种芯片搭配实现三种方案: L1-L2:1 个骁龙 8540,面向主动安全功能(AEB、TSR、LKA 等),算力 30 TOPS,功耗 15 W; L2-L4:2 个骁龙 8540,面向辅助驾驶(HWA、自动泊车、TJA 等),算力 120TOPS,功耗 30W; L5:2 个骁龙 8540+2 个骁龙 9000,面向完全自动驾驶,算力 700TOPS,功耗 150W。
2.3.3.3 特斯拉
特斯拉初期集中软件层面,硬件依托芯片厂商提供,后期凭借强大研发能力开发出自研计算 FSD 平台,可 以更好适配自身车型,最大程度发挥芯片性能。特斯拉是用低成本策略,通过软件把硬件发挥到极致,不堆料。
HW1.0 版本(2015.10):芯片 SoC 由 Mobileye(eyeQ3)提供,由于 Mobileye 黑盒子属性,可开发性较差, 因此第一代后被特斯拉弃用; HW2.0 版本(2016.10):由英伟达(Parker)提供,配置采用 1 个 Parker+1 个 GPU,相当于是英伟达给特斯 拉的特供版,属于特斯拉采取的过渡策略; HW2.5 版本(2017.8):由英伟达提供,采用 2 个 Parker+1 个 GPU,性能配置与英伟达 Drive PX2 一致;
2.2.3.4 蔚来汽车

全新 NIO Adam 域控制器是目前功能最强大的平台。凭借四个 NVIDIA Orin SoC,Adam 实现了超 1000 TOPS 的性能。其中两颗主控芯片实现全栈计算,包括多方案相互校验的感知、多源组合定位、多模态预测和决策; 一颗独立的冗余备份芯片确保安全;一颗训练专用芯片满足用户个性化驾驶体验。

三、软件架构:高度分层化和模块化
3.1 虚拟机:软件最底层,使不同操作系统共用同一硬件资源
3.1.1 是什么:模拟硬件系统的计算机系统仿真器
3.1.1.1 虚拟机介绍
汽车电子电气系统中不同的 ECU 提供不同的服务,具有不同的优先级,对底层 OS 的要求也不一样。例如 汽车仪表系统与汽车的动力密切相关,它要求其具有高实时性、高可靠性和高安全性,因此主要以 QNX 操作系 统为主,而信息娱乐系统主要提供人机交互控制平台,追求多样化的应用服务,所以 Linux 和 Android 等 OS 也 能够胜任。那么如何使不同类型的 OS(操作系统)运行在同一套硬件上呢,最直接的路径就是虚拟化 (Virtualization)。 所谓的“虚拟”即使用某种方式隐藏底层物理硬件的过程,从而使多个 OS 可以共享这些硬件。而这些 Guest OS(访客操作系统)和其实现的应用功能就可以被视作一个虚拟机。虚拟机(Virtual Machine, VM)是计算机系统的仿真器,通过软件模拟具有完整硬件系统功能的、运行在一个完全隔离环境中的完整计 算机系统,能提供物理计算机的功能。通过虚拟机 VM,多个相互隔离的、不同的系统便可以在同一硬件机器 上运行。
在传统模式下,实现某一特定功能就需要一套单独且完整的 OS 和与之对应的独立的硬件,具体到汽 车领域,就需要大量的 ECU、线束、接插件的实体成本以及多次生产、多次研发、多次测试的成本。而 Hypervisor 的工作原理是通过允许或者限制访问 CPU、内存等外部物理硬件上的资源,来定义每个 VM 可 用的功能。当一个特定的 Guest OS 开始消耗更多的资源时,Hypervisor 会把它转移到另一个需求较少的虚 拟机上。除此外,Hypervisor 可以为每个虚拟机分配不同的资源,从而将各种计算单元进行整合、算力共享, 以期达到降低成本的目的。例如,CPU 上的处理时间可以划分为多个时片,并根据需要分配给不同的虚拟机, 一个虚拟机可以访问多个 CPU 内核。类似地,存储器和其他外设硬件可以共享或分配给单个虚拟机。虚拟机 VM 无需知道或根本不知道彼此的存在,并且无法访问未提供给它们的资源。因此,Hypervisor 也被称为虚拟机 管理程序 (Virtual Machine Manager , VMM)。
在汽车领域,虚拟机技术率先在智能座舱中得到应用。座舱的智能化,就是对传统座舱所进行的数字化、 液晶化与集成化。智能座舱是由不同的座舱电子元器件组合而成的完整体系,它包括数字化全液晶仪表盘、车 载信息娱乐系统、抬头显示系统 HUD 及车联网模块等。如果是在传统模式下,如此多功能的应用势必会造成大 量硬件的堆砌和杂糅,增加造车成本。另外由于智能座舱中各个部分的安全要求不同,需要运行不同的操作系 统(比如 QNX 负责仪表、安卓负责信息娱乐系统),传统的软硬件搭配方案无法有效地将不同 OS 整合起来。
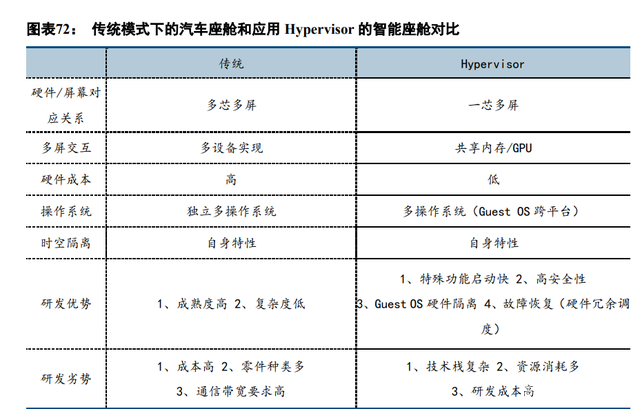
通过引入 Hypervisor 虚拟机技术,就相当于给了智能座舱一个操作系统,灵活地按照产品需求在不同的 Guest OS(VM)中分配硬件和软件资源,比如协调不同的芯片、不同芯片底层软件、不同应用层软件,让整个 架构和系统高效地工作起来,由于各个虚拟机之间的严格隔离,所以系统的冗余度较高,当一个虚拟机中的应 用程序出现故障时,只会影响分配给它的内存,而不会影响其它虚拟机。另外,对 OS 的简单修改就能使之在 多个 VM 间共享内存,新旧 VM 软件可因此共存,整个计算平台的系统灵活性和扩展性比起传统模式要好。例 如,在 Visteon 的 SmartCore 域控制器,在 Visteon 自身以及 QNX 或者 Integrity 等 Hypervisor 助力下,使得 Visteon 自家的软件堆栈与 Phoenix和 Android 等其他类型的车载娱乐信息 OS 能够集成在一起,从而在人机交互终端能 够发挥出不同的应用功能。
3.1.2 趋势:域融合趋势下,虚拟机技术将成为必须项
Hypervisor 提供了在同一硬件平台上承载异构操作系统的灵活性,同时实现了良好的高可靠性和故障控制 机制,以保证关键任务、硬实时应用程序和一般用途、不受信任的应用程序之间的安全隔离,实现了车载计算 单元整合与算力共享。 当前 Hypervisor 已经成为智能座舱所采用的技术方案,未来随着自动驾驶域控制器与智能座舱域控制器融 合,在高算力芯片上同时实现自动驾驶与智能座舱功能,Hypervisor 将成为必选方案。
3.1.3 格局:黑莓绝对龙头
目前全球虚拟化系统供应商几乎全部来自海外,由于车载虚拟机(Automotive Hypervisor)技术有着较高的 安全等级要求,因此能提供此类产品的供应商较少。该领域主要玩家有黑莓 Blackberry(QNX)、英特尔 Intel (ACRN)、OpenSynergy(COQOS)、Green Hills(Integrity)、大陆 Continental(L4Re)、Wind River Systems、 NXP、Siemens、Luxoft 等等。
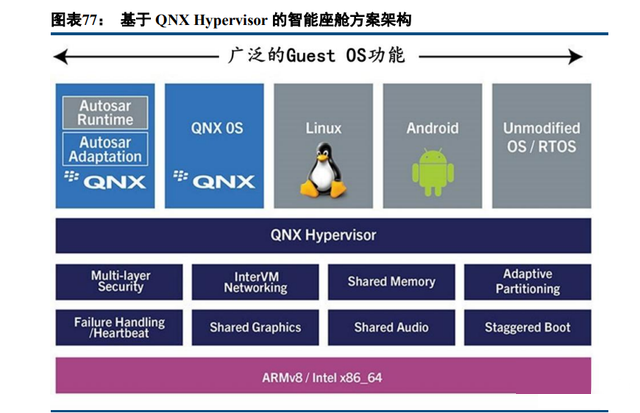
1. QNX Hypervisor: 其中黑莓旗下的 QNX Hypervisor 是目前公认最安全最成熟的智能座舱 Hypervisor 操作系统,QNX 由于同 时获得了工业级(IEC 61508 SIL-3 级)和车规级(ISO 26262 ASIL-D 级)认证,占据了 60%的市场份额,可谓 一家独大。 从产品上讲,黑莓 QNX Hypervisor 属于 Type 1 型虚拟机管理系统,上面可以适配不同类型的 Guest OS 组 合帮助 OEM 和 Tier 1 为传统 ECU 以及下一代 ECU 和域控制器设计和开发高性能、安全、可靠的车载应用程 序。 BlackBerry QNX 软件以标准为基础,提供通用的开发工具,以满足并兼容车辆中安全关键型和非安全型 ECU 的需求,并为安全通信、安全图形、安全系统库和中间件提供解决方案。
2. ACRN Hypervisor: 2018 年 Linux 嵌入式大会上发布的 ACRN Hypervisor,是一款灵活、轻量级的参考 hypervisor,兼顾实 时性和关键安全性,并通过开源平台为精简嵌入式开发进行优化。ACRN 定义了设备 Hypervisor 的参考堆栈和 体系结构,用于在统一系统上运行安全管理的多个 Guest OS 软件子系统。ACRN Hypervisor 属于 Type 1 Hypervisor,直接在裸机硬件上运行,适用于各种 IoT(物联网)和嵌入式设备(Embedded Device)解决方案。 ACRN Hypervisor 解决了数据中心管理程序和硬分区管理程序之间当前存在的空白。ACRN Hypervisor 架构将系 统划分为不同的功能域,并精心选择了针对物联网和嵌入式设备的用户虚拟机共享优化。
3. OpenSynergy – COQOS Hypervisor COQOS Hypervisor 软件开发包(SDK)由 OpenSynergy 和瑞萨 Renesas 开发,可在 SoC 硬件上实现多种功 能的融合,同时使不同关键性的系统(分配给不同的 ASIL 级别,例如 QM 级,A 级,B 级等)之间不受干扰。 Hypervisor 技术是 COQOS Hypervisor SDK 的核心。通过 Hypervisor 虚拟化管理技术,可以在单独的虚拟机中运 行多个 Guest OS(包括 Linux,Android,AUTOSAR 或其他 OS)。COQOS Hypervisor 的一个典型的使用案例 是座舱控制器,它可以在单个处理器上同时运行仪表板和车载信息娱乐系统。
4. Greenhill- INTEGRITY Multivisor INTEGRITY Multivisor 是业界唯一经过安全认证的架构,可在各种多核 SoC 硬件上同时运行一个或多个 Guest OS 以及关键任务功能。INTEGRITY Multivisor 是专门为了解决嵌入式设备遇到的困难而设计的,它能够 在不影响安全、或性能的情况下实现快速、和成本效益最高的复杂系统设计。
3.2 操作系统:软硬件隔离的基础
3.2.1 是什么:操作系统承上启下,引领智能汽车升级
从 20 世纪 90 年代开始,随着车载电子装置功能的日益丰富以及外部交互/接口标准的种类增加,这类基于 微控制芯片的嵌入式电子产品逐渐需要采用类似个人电脑的软件架构以实现分层化,平台化和模块化,提高开 发效率的同时降低开发成本。因此,汽车电子产品才逐步开始采用操作系统。 操作系统(Operating System,OS)是指控制和管理整个计算系统的硬件和软件资源,并合理地组织调度计 算机的工作和资源,以提供给用户和其他软件方便的接口和环境的程序集合。智能设备发展到一